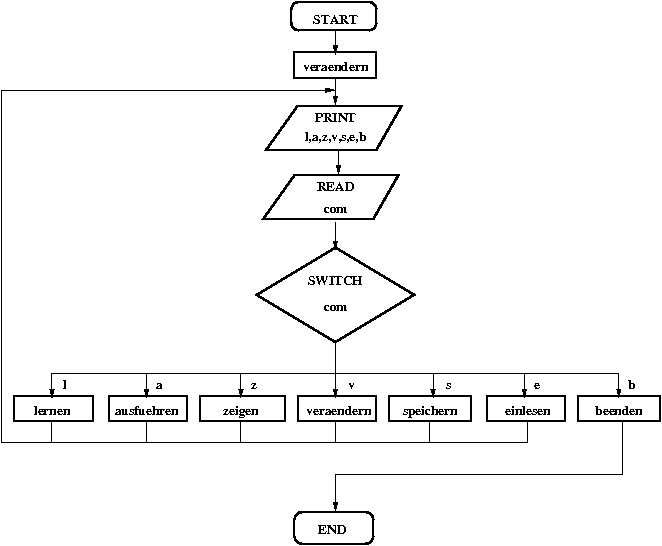
Flussdiagramm des Programms PERCEPT2.C
Da uns das Flussdiagramm inzwischen vertraut sein sollte,
beginnen wir die Lösung der Aufgabe direkt mit einem Blick auf das Listing
des Programms PERCEPT2.C. Hierbei sollten Sie sich klar machen, dass sich
dieses Programm vom Programm PERCEPT1.C nur dadurch unterscheidet, dass
man in der C-Funktion "veraendern" a priori die Anzahl
der Trainingsdaten t sowie die maximal zu
durchlaufende Anzahl von Trainingszyklen s_max
angeben kann und somit
die stets zu wiederholende Eingabe des Trainingsdatensatzes von Hand
entfällt. Hier ist also die iterierte Perceptron-Lernregel im engeren
Sinne implementiert, während sie in PERCEPT1.C nur implizit durch
wiederholtes manuelles Eingeben simuliert werden kann.
Dies hat allerdings auch sofort die Konsequenz, dass zwei
x-Leseroutinen
benötigt werden: eine zum Einlesen der im Ausführ-Modus zu testenden
Eingabevektoren ("lese_test_x") und eine, ein Feld anlegende Routine zum
Einlesen der x-Trainingsassoziationen ("lese_x"). Bisher konnte ja
bei den Programmen LINASSOZ.C und PERCEPT1.C auf die Speicherung der
x-Trainingseingänge verzichtet werden, so dass eine Leseroutine,
nämlich "lese_x", ausreichend war. Ferner sollte man für das
Verständnis des Programms wissen, dass in der C-Funktion "lernen" mit der
Variablen s die durchlaufenen Lernzyklen gezählt werden und mit
der Variablen err der im s-ten Zyklus vorhandene summierte absolute Fehler
nachgehalten wird. Schließlich ist die Lernroutine durch einen kleinen
Modulo-Trick so konstruiert, dass stets maximal 100 Lernzyklen auf dem
Bildschirm dokumentiert werden (lokale Variable z). Abgebrochen wird die
Lernroutine entweder durch fehlerfreies Arbeiten im Ausführ-Modus
(err = 0) oder durch das Erreichen der Maximalzahl zulässiger
Trainingszyklen ( s=s_max ).
Burkhard Lenze
Im Februar 2009