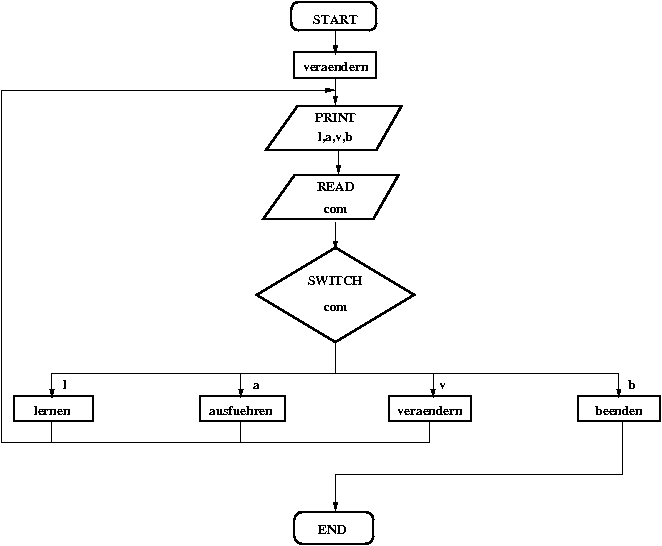
Flussdiagramm des Programms HOPSI-PI.C
Wir beginnen die Lösung der Aufgabe mit einem Blick auf das Flussdiagramm
des Programms HOPSI-PI.C. Man erkennt, dass bei diesem Programm wieder
auf die C-Funktionen "zeigen", "speichern" und "einlesen" verzichtet
wurde. Dies liegt darin begründet, dass das Zeigen, Speichern und Einlesen
der Gewichte des Sigma-Pi-Hopfield-Netzes 2-ter Ordnung zwar prinzipiell
möglich ist, allerdings relativ speicherintensiv ist und bei Visualisierung
wenig hilfreiche Informationen entstehen. Aus diesem Grunde wurde auf die
entsprechenden Routinen verzichtet.
Mit Blick auf das Listing des
Programms HOPSI-PI.C
ist wesentlich, dass die Gewichte bis zur Ordnung 2 im Hebb-Lern-Modus
bestimmt werden (Berücksichtigung multiplikativer Interferenzen mit
bis zu drei Faktoren) und diese Gewichte höherer Ordnung natürlich
auch im Ausführ-Modus eingesetzt werden müssen. Vergleicht man
die dazu implementierte C-Funktion "ausfuehren" mit der in Kapitel 5 in
Definition 5.3.3 gegebenen Quasi-PASCAL-Notation des Ausführ-Modus,
so sollte auffallen, dass die Summation über die hier maximal
dreielementigen Teilmengen R in {1,2,...,n} mit j in R
ersetzt wird durch die geschachtelte Summation über j=1...n,
i=1...n und k=1...i-1.
Dabei fließt ein, dass in der
C-Funktion "veraendern" zunächst alle Gewichte mit Null initialisiert
werden. Da in der C-Funktion "lernen" im Rahmen des Hebb-Lern-Modus
nicht auf ww[i][j] mit i=j und www[i][j][k] mit i=j
oder i=k
oder j=k zugegriffen wird, bleiben diese Gewichte auch auf Null gesetzt und
haben keinen Einfluss in der C-Funktion "ausfuehren". Desweiteren wird in der
C-Funktion "lernen" durch Symmetrisierung dafür gesorgt, dass stets
ww[i][j]=ww[j][i] sowie
www[i][j][k]=www[i][k][j]=www[j][i][k]=www[j][k][i]=www[k][j][i]=www[k][i][j]
gilt. Lässt man auch diese
Information einfließen, so ist klar, dass die C-Funktion "ausfuehren"
exakt den Ausführ-Algorithmus aus Definition 5.3.3 für maximal
dreielementige Teilmengen R aus {1,2,...,n} realisiert.
Ansonsten ist
das Programm -- bis auf einige Ausdünnungen -- in vielen Punkten mit dem
Programm KOSKOBIL.C identisch und sollte deshalb keine Schwierigkeiten
bereiten. Der wesentliche Unterschied besteht lediglich darin, dass es
für dasselbe autoassoziative Problem nur die Hälfte an Neuronen --
allerdings Sigma-Pi-Neuronen -- benötigt.
Burkhard Lenze
Im Februar 2009