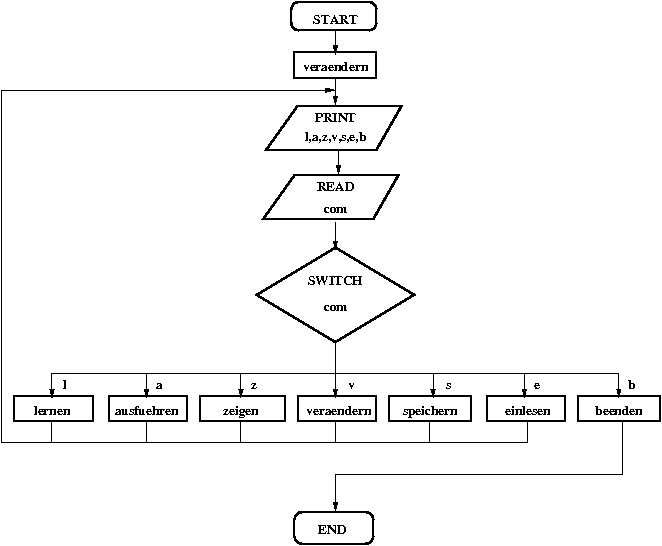
Flussdiagramm des Programms BACKPRO1.C
Obwohl es sich bei dem
Programm BACKPRO1.C erstmals um ein dreischichtiges neuronales Feed-Forward-Netz
handelt, ist der prinzipielle Aufbau
gemäß Flussdiagramm vollkommen identisch
mit dem der zweischichtigen Netze (linearer Assoziierer oder Perceptron); aus
diesem Grunde sollte das Verständnis der grundsätzlichen Struktur des
Programms keine Schwierigkeiten machen. Die Unterschiede zu den bisherigen
Netzimplementierungen werden aber sehr schnell deutlich, wenn man sich das
Programm im Detail ansieht: Zunächst muss BACKPRO1.C als dreischichtiges
Feed-Forward-Netz eine Reihe zusätzlicher Felder und Parameter bereitstellen,
die für Netze dieses Typs charakteristisch sind, z. B. das Matrixfeld
der Ausgangsgewichte, die Anzahl verborgener Neuronen, den maximalen
Ausgabefehler, den Stauchungsparameter für die Transferfunktion sowie
die Lernrate für die Backpropagation-Lernregel. Mit Blick auf die
benötigten C-Funktionen ist ferner wesentlich, dass es sich bei der
Transferfunktion "T" um die mit dem Stauchungsparameter beta
skalierbare beliebig oft differenzierbare Fermi-Funktion T_F handelt.
Desweiteren wird mit der Funktion "TS" unmittelbar die für den
Backpropagation-Algorithmus benötigte Ableitung der jeweiligen
beta-skalierten Transferfunktion bereitgestellt. Darüber hinaus sind
natürlich insbesondere die Funktionen "lernen" (Backpropagation-Lernen)
und "ausfuehren" (Ausführ-Modus für dreischichtige Feed-Forward-Netze)
von zentraler Bedeutung für die Funktionsweise des
BACKPRO1.C-Programms und sollten nach Vergleich mit den in Kapitel 3
formulierten Algorithmen und durchgeführten Handrechnungen in ihren
wesentlichen Eigenschaften durchschaut werden. Speziell die den
Backpropagation-Algorithmus realisierende C-Funktion "lernen" sollte
noch einmal im Detail mit der in Definition 3.5.1 gegebenen algorithmischen
Notation verglichen werden und als "Herzstück" des Programms verstanden
werden. Wesentlich ist in diesem Kontext wieder -- wie bereits beim
Perceptron-Netz PERCEPT2.C --, dass mit der globalen Variablen s
die durchlaufenen Lernzyklen gezählt werden sowie mit der lokalen
Variablen err der im s-ten Zyklus vorhandene summierte quadrierte
Fehler nachgehalten wird. Die Lernroutine ist außerdem wieder mit
einem kleinen Modulo-Trick so konstruiert, dass maximal 100 Lernzyklen
auf dem Bildschirm dokumentiert werden (lokale Variable z). Abgebrochen wird
die Lernroutine entweder durch Unterschreiten des vorgegebenen maximalen
Ausgabefehlers (err<epsilon) oder durch Erreichen der Maximalzahl
zulässiger Trainingszyklen (s=s_max). Schließlich
sollte nach
den Bemerkungen aus Kapitel 3 ebenfalls klar sein, dass wir die Gewichte und
Schwellwerte in diesem Programm nur aus Gründen der Reproduzierbarkeit
der Resultate in der C-Funktion "veraendern" mit Null initialisieren
und somit bewusst relativ schlechte
Simulationsresultate in Kauf nehmen. In der Praxis würde man die
Netzparameter Random-initialisieren, das Netz eine Weile lernen lassen,
bei guten Resultaten zufrieden sein, bei schlechten erneut
Random-initialisieren, etc..
Burkhard Lenze
Im Februar 2009